
COLING是国际计算语言学会议,是自然语言处理和计算语言学领域的顶级会议之一,每两年举办一次。今年的 COLING 大会于10月12日到10月17日在韩国庆州召开。昨日,COLING 2022公布了获奖论文信息,其中苏州大学的【Fast and Accurate End-to-End Span-based Semantic Role Labeling as Word-based Graph Parsing】被评为最佳论文。

论文题目:Fast and Accurate End-to-End Span-based Semantic Role Labeling as Word-based Graph Parsing
论文机构:苏州大学
论文作者:周仕林、夏庆荣、李正华、张宇、洪宇、张民
论文链接:https://aclanthology.org/2022.coling-1.365.pdf(opens new window)
代码链接:https://github.com/zsLin177/SRL-as-GP(opens new window)
主要贡献:片段语义角色标注目前的两种主流方法分别为:基于BIO序列标注的方法和基于片段的图解析方法。该论文提出一种新的基于词的图解析方法,将片段图解析方法的搜索空间从O(n^3)降低到O(n^2),从而大幅度提升了模型的训练和解码效率,且性能超过了前人结果。
01摘要
该论文的出发点是将端到端基于片段的(span-based)语义角色标注(SRL)转换为基于词的(word-based)图解析(graph parsing)任务。其中主要的挑战是如何在词级别上表示片段信息。该论文通过借鉴中文分词(CWS)和命名实体识别(NER)的研究成果,提出了四种不同的图表示方案,即BES、BE、BIES和BII。此外,根据SRL结构的约束,作者还提出了一个简单的约束Viterbi过程,以保证输出图的合法性。作者在两个广泛使用的CoNLL05和CONLL12基准数据集上进行了实验。结果表明,在端到端和谓词给定的所有设置下,在没有和有预训练语言模型的情况下,该论文提出的基于word的图解析方法都取得了比以前方法更好的性能。更重要的是,该论文提出的方法推理速度很快,在不使用预训练模型(PLMs)的情况下,每秒可以解析669个句子;在使用PLMs的情况下,每秒可以解析252个句子。
02背景介绍
语义角色标注是自然语言处理(NLP)中一个必不可少的任务,它使用谓词-论元的结构去表示一个浅层的句子语义。SRL结构能够帮助解决很多下游NLP任务,比如机器翻译和问答。
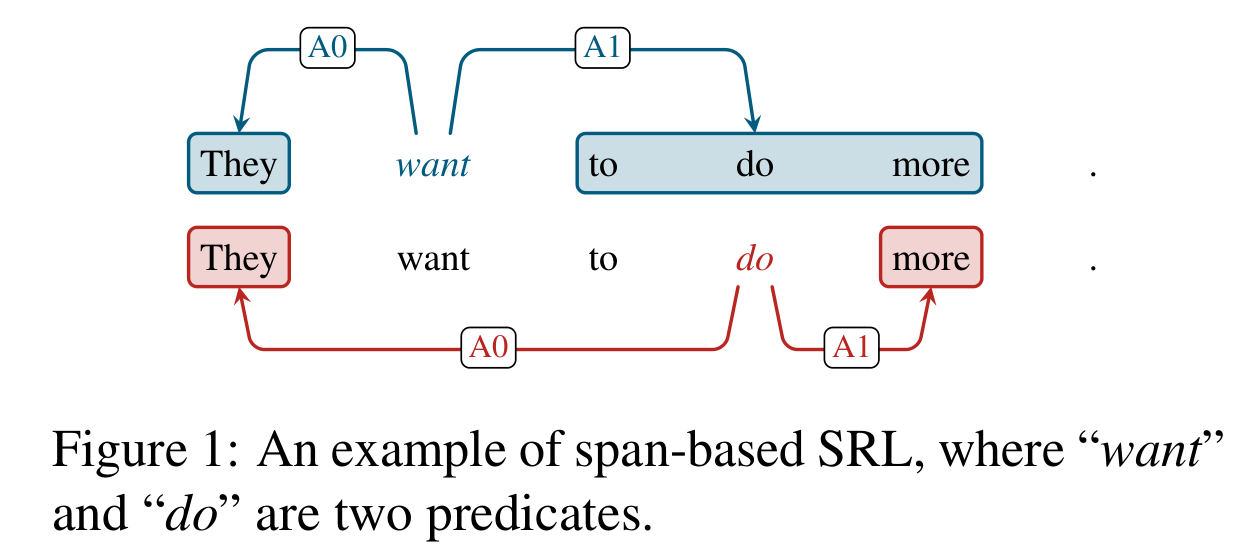
SRL存在两个形式,分别基于词(word-based)和片段(span-based),划分依据取决于一个论元是包含单个单词还是一个片段。对比基于word的SRL来说,基于span的SRL是更加复杂的。上图1也展示了一个基于span的样例,语义角色被边的标签所划分,比如施事(agent) “A0”和受事(patient) “A1”。
随着深度学习的发展,尤其是预训练模型的提出,基于span的SRL近些年也取得了巨大的进展,吸引了研究人员们的关注。该工作主要关注端到端基于span的SRL任务,并提出了一个模型可以同时识别输入句子中的谓词和论元。这里端到端是指一个句子中所有的谓词和论元都是通过单个模型同时推断得到的。
基于span的图解析方法直接把所有的词片段考虑为候选论元节点,并将他们链接到谓词节点上。然而,对于一个句长为n的句子,计算候选谓词和候选论元的复杂度分别为O(n)和O(n^2),从而导致了一个非常大的搜索空间O(n^3),使得这种方法效率较低。在以往的一些工作,通常使用启发式剪枝技术来提高效率。
针对端到端基于span的 SRL,该论文首次提出了一种基于word的图解析方法。由于图网络中的每个节点只对应于单个单词,关键的挑战是如何在基于单词的图中表示基于span的论元。一旦解决了这个问题,就可以在现有的基于单词的图解析模型基础上构建解析器。该工作的主要贡献点如下:
1: 提出了一种新的基于word的图解析方法,可以用于端到端基于span的SRL。通过简单的修改,该方法也可以应用于谓词给定的设置。
2: 借鉴中文分词(CWS)和命名实体识别(NER)的研究思路,作者提出了4个图方案,其中BES方案稳定优于其他方案。
3: 同时,由于图解析模型可能会输出不合法的图,不能正确地转换为SRL结构。为了解决这一问题,作者提出了一个简单的约束Viterbi过程(constrained Viterbi procedure),用于非法图的后处理。
4: 作者在CoNLL05和CoNLL12基准数据集上进行了实验。在端到端和谓词给定的所有设置下,无论是否使用PLMs,该论文提出的方法都能取得比以前方法更好的性能。并且模型推断速度要快得多,在不使用PLMs和使用PLMs的情况下,每秒分别可以分析669/252个句子。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢